AI(人工知能)技術は、今や私たちの生活やビジネスのあらゆる側面に深く浸透しています。自動運転車から医療診断、金融取引の意思決定まで、AIは計り知れない価値を生み出していますが、その利用の拡大と高度化は新たなリスク をもたらしています。それが、本記事のテーマである「AIセキュリティ 」です。
AIセキュリティは、従来のサイバーセキュリティの概念を超え、AIシステム特有の脆弱性を標的とする攻撃から、データ、アルゴリズム、そしてAIの意思決定プロセス全体を保護するための、専門的かつ複合的な対策を指します。
本記事では、AIセキュリティの基本的な定義から、なぜ今それが重要なのか、そしてAIシステムを標的とする具体的な脅威の種類、さらにはそれらの脅威に対抗するための具体的な対策までを、包括的かつ専門的に解説します。
1. AIセキュリティの定義と従来のセキュリティとの違い
1-1. AIセキュリティとは何か?
AIセキュリティ(AI Security、またはAI/ML Security)とは、AIシステム(特に機械学習モデル)の完全性、可用性、および機密性を確保するための専門分野 です。具体的には、AIモデルが学習に使用するデータ、モデルそのもの(アルゴリズムと重み)、そしてモデルが出力する結果や意思決定を、悪意ある操作や予期せぬエラーから守ることを目的とします。
従来のサイバーセキュリティが、システムのネットワークやアプリケーション層の脆弱性(例:SQLインジェクション、OSのパッチ未適用)を主に扱ってきたのに対し、AIセキュリティは**「モデルのロジック」と「データの統計的特性」に内在する脆弱性**に焦点を当てます。
1-2. 従来のセキュリティとの決定的な違い
AIシステムが従来のシステムと異なるのは、その振る舞いが**「アルゴリズムと学習データの相互作用」**によって決定される点にあります。この特性が、新たな攻撃ベクトルを生み出します。
特徴 従来のサイバーセキュリティ AIセキュリティ 主な防御対象 ソフトウェア、ネットワーク、ハードウェア、ユーザー認証 学習データ、AIモデル(アルゴリズムとパラメータ)、モデルの推論結果 攻撃の標的 サーバーダウン、データ流出、不正アクセス、マルウェア感染 モデルの誤分類 、プライバシー侵害 、モデルの機能停止 主な脆弱性 コードのバグ、設定ミス、認証の不備 データ汚染、モデルの過学習、敵対的摂動への脆弱性
AIセキュリティの核心は、モデルの「信頼性(Trustworthiness)」を守ること にあります。モデルが間違った判断を下すように仕向けたり、学習データから機密情報が漏洩したりするのを防ぐことが、最も重要な課題となります。
2. なぜ今、AIセキュリティが重要なのか?
AIセキュリティへの関心が高まっている背景には、AI技術の普及と、それに伴うリスクの深刻化があります。
2-1. AIの意思決定への依存度の高まり
金融、医療、インフラ管理など、人命や社会の安定に直結する分野でAIが意思決定の役割を担うようになっています。
自動運転: AIモデルが操作を誤れば、人命に関わる事故につながります。医療診断: 悪意あるデータでAIが訓練されれば、誤った診断を下すリスクがあります。金融取引: AIの不正な操作により、市場の混乱や巨額の損失が発生する可能性があります。
AIの判断が不正に操作された場合の影響は、従来のデータ流出よりも遥かに甚大であり、**「物理的な被害」や「社会的な機能不全」**に直結するリスクを内包しています。
2-2. AI特有の「敵対的(Adversarial)」な脅威
AI技術は本質的に、人間の目には認識できない微細な変化に影響を受けやすいという特性があります。この特性を利用した「敵対的攻撃 」は、従来のセキュリティ対策では検出が極めて困難です。
攻撃者は、システムに侵入せずとも、巧妙に細工された入力データを与えるだけでAIの判断を狂わせることが可能です。この**「外部からのロジック操作」**こそが、AIセキュリティを従来のセキュリティと区別する最大の理由です。
2-3. 法規制への対応
欧州連合の**AI法案(EU AI Act)**を筆頭に、AIの「リスクベース」の規制が世界的に進んでいます。高リスクなAIシステムに対する透明性、ロバスト性(堅牢性)、データガバナンスの要求が高まっており、AIセキュリティ対策は単なるリスク管理ではなく、事業継続のためのコンプライアンス の要件となりつつあります。
3. AIシステムを標的とする具体的な脅威(攻撃の種類)
AIセキュリティの脅威は、大きく分けてAIモデルの学習フェーズ(Training Phase)を標的とするものと、モデルの運用フェーズ(Inference Phase)を標的とするもの、そしてプライバシー侵害を目的とするものに分類されます。
3-1. モデルの学習フェーズへの攻撃(データ汚染)
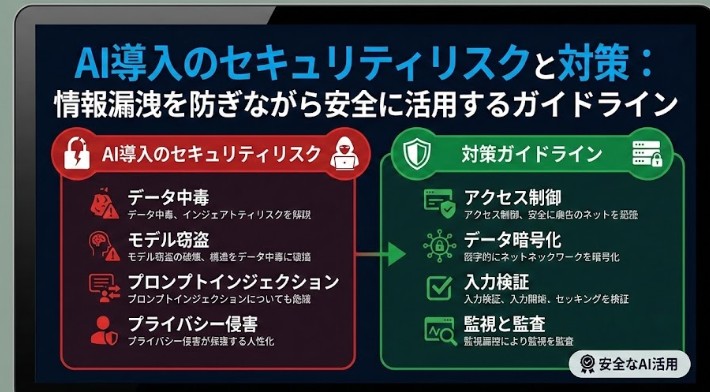
3-1-1. 💡データポイズニング(Data Poisoning Attack)
概要: AIモデルの訓練データに、悪意を持って改ざんされたデータや誤ったラベル付けがされたデータを混入させる攻撃です。目的: モデルの学習プロセスを意図的に歪め、特定の入力に対して間違った出力をするように仕向けます。
例: スパムフィルターに大量の誤分類データを混入させ、特定の重要メールが「スパムではない」と誤認識するように訓練させる。
3-1-2. 🎯バックドア攻撃(Backdoor Attack / Trojan Attack)
概要: データポイズニングの一種ですが、攻撃者は特定の**「トリガー」**(例:画像内の目立たない小さなパッチ)を持つデータセットを混入させます。目的: 通常の入力に対しては正しく機能するものの、トリガーが付加された入力が与えられた場合にのみ、攻撃者が望む誤った出力を出すようにモデルに「裏口」を仕込みます。これは、モデルが既に訓練され、サービスとして提供されている場合に特に危険です。
3-2. モデルの運用フェーズへの攻撃(推論時の操作)
3-2-1. 🖼️敵対的摂動(Adversarial Example Attack)
概要: 人間の目にはほとんど知覚できない、**非常に微細なノイズ(摂動)**を元のデータ(画像、音声など)に加えることで、AIモデルがそれを全く別のものとして誤分類するように誘導する攻撃です。
例: わずかなピクセルノイズを加えることで、AIには「停止」標識が「徐行」標識として認識されるようにする。
重要性: 攻撃者はモデルの内部構造を知っているホワイトボックス攻撃 と、出力結果から類推して攻撃を行うブラックボックス攻撃 の両方で実行可能です。これは、AIセキュリティの中で最も研究が進んでいる分野の一つです。
3-2-2. ❓モデル盗難(Model Stealing / Extraction Attack)
概要: 攻撃者が、提供されているAPIなどを通じて繰り返し問い合わせを行い、その応答(出力)を分析することで、AIモデルの内部構造や学習済みパラメータ を推定し、同等の機能を持つコピーモデル を作成する攻撃です。目的: 攻撃者は、オリジナルのモデル開発に投じられた知的財産(時間、データ、計算資源)を盗み、自社の製品に使用したり、コピーモデルに対してより高度な敵対的攻撃を開発したりするために利用します。
3-3. プライバシー関連の攻撃(情報漏洩)
3-3-1. 🕵️メンバーシップ推論攻撃(Membership Inference Attack)
概要: 攻撃者が特定のデータポイント(例:ある個人の医療記録、クレジットカード情報など)が、AIモデルの訓練に使用されたかどうか を推測する攻撃です。メカニズム: モデルは訓練に使用されたデータに対して「過剰適合(overfit)」する傾向があるため、そのデータに対してより「自信のある」応答を返します。この応答の差異を分析することで、機密性の高い個人のデータがモデルに含まれていたかどうかが特定される可能性があります。
3-3-2. 🏗️モデル反転攻撃(Model Inversion Attack)
概要: モデルの出力(例:人の顔のカテゴリ)と、そのモデルの特性を利用して、**訓練に使用された元の入力データ(例:人の顔の画像そのもの)**を部分的に復元しようとする攻撃です。リスク: 特に顔認識、ゲノムデータ、医療画像など、機密性の高い個人情報を扱うAIモデルにおいて、プライバシーの深刻な侵害につながります。
4. AIセキュリティを実現するための具体的な対策
AIセキュリティは、単一のツールや技術で解決できるものではなく、データ準備からモデル運用、そして組織的なガバナンスに至るまでの**包括的なアプローチ(Defense-in-Depth)**が必要です。
4-1. データレベルの対策:堅牢な学習データの確立
AIセキュリティの土台は、学習データの品質と完全性にあります。
入力バリデーションとサニタイズ: 訓練データを取り込む前に、データが期待される形式、範囲、統計的特性を満たしているかを厳格にチェックします。異常値や統計的に不自然なデータは排除または隔離します。データセットの暗号化とアクセス制御: 訓練データはAIモデルの「核」であるため、最高レベルの機密データとして扱い、転送中および保存時に強力な暗号化を適用し、アクセス権限を厳密に管理します。連合学習(Federated Learning)の活用: 複数のデバイスや組織が、データそのものを共有せず に、ローカルで学習したモデルの重み(パラメータ)の更新情報のみ を共有し、中央サーバーで統合する手法です。これにより、データプライバシーを保ちつつモデルの学習を進めることができます。
4-2. モデルレベルの対策:堅牢なモデルの設計と訓練
敵対的攻撃に対する耐性を高めるための対策が不可欠です。
4-2-1. 🛡️敵対的訓練(Adversarial Training)
概要: AIモデルを学習させる際、意図的に敵対的サンプル (微細なノイズを加えて攻撃用に改ざんされたデータ)を生成し、それを通常のデータと合わせてモデルに学習させる手法です。効果: モデルは「わずかな変化」に対する感度を下げ、攻撃者が仕掛ける敵対的摂動に対して頑健性(ロバスト性)を高めることができます。これは、現時点で最も効果的な防御策の一つです。
4-2-2. 📐モデルのロバスト性評価
概要: モデルをデプロイする前に、通常の性能評価だけでなく、敵対的攻撃シミュレーション を含む専門的なテスト(レッドチーミング)を実施します。評価項目: 様々なノイズレベルや攻撃手法(FGSM, PGDなど)に対するモデルの誤分類率を計測し、許容できるセキュリティレベルを満たしているかを検証します。
4-2-3. 🌊ディープ・フォグ(Deep Fog)などの防御メカニズム
概要: モデルの入力層や中間層に、入力データをランダム化したり、ノイズを付加したりする**「防御層」**を組み込む手法です。効果: 敵対的サンプル特有の微妙なパターンを「ぼかす」ことで、攻撃の有効性を低下させます。
4-3. 運用・インフラレベルの対策:デプロイ後の保護
モデルがサービスとして稼働し始めてからも、継続的な監視と保護が必要です。
モデルの監視と異常検出: リアルタイムでモデルの入出力データを監視し、統計的に異常なパターン や急激なパフォーマンスの低下 を検出するシステムを導入します。異常なリクエストの集中は、モデル盗難やサービス拒否攻撃の兆候である可能性があります。出力のサニタイズと制限: サービスがユーザーに返すAIの出力(例:テキスト生成AIの応答)に対して、不適切な情報や機密性の高い情報を漏洩していないかチェックするフィルタリング機構を設けます。APIアクセス制限とレートリミット: モデルAPIへのアクセスを厳しく制限し、短時間に大量の問い合わせを行うユーザーに対してはレートリミット(アクセス制限)を設けることで、モデル盗難攻撃のコストを上げ、実行を困難にします。モデルウォーターマーキング(知的財産保護): モデルのパラメータに、モデル開発者のみが知る「電子透かし(ウォーターマーク)」を埋め込む手法です。モデルが盗難された場合、そのコピーモデルの動作をテストすることで、この透かしを検出し、知的財産権の侵害 を立証するための証拠として利用できます。
5. AIセキュリティと組織的ガバナンス
技術的な対策に加えて、組織全体でAIの安全性を確保するための枠組みが不可欠です。
5-1. AIリスク評価(AI Risk Assessment)の導入
AIシステムを開発・導入する前に、そのシステムが社会やビジネスに与える影響度に基づき、リスクを評価します。
高リスクAI: 自動運転、重要な医療診断、信用スコアリングなど。最も厳格なセキュリティ対策と規制への適合が求められます。低リスクAI: スパムフィルター、一般的なレコメンドシステムなど。評価プロセス: どのような脅威(データポイズニング、敵対的攻撃など)が最も現実的か、その脅威が実現した場合の損失はどの程度かを分析し、必要なセキュリティ投資を決定します。
5-2. 透明性と説明責任の確保(Explainability and Accountability)
モデルがなぜその判断を下したのかを説明できる能力(説明可能性:XAI – eXplainable AI )は、セキュリティと密接に関連しています。
意図しない振る舞いの特定: モデルの出力が異常であった場合、XAIツールを利用して、どの入力データや特徴量がその決定に最も強く影響したかを分析することで、攻撃による不正なロジックを早期に特定できます。説明責任: 攻撃や誤判断が発生した場合、責任の所在を明確にし、迅速に是正措置を講じるための基礎となります。
5-3. 専門知識の育成と連携
AIセキュリティは、従来のセキュリティ専門家とAI/MLエンジニアの知識の融合を必要とします。
クロスファンクショナルチーム: セキュリティチームとAI開発チームが密接に連携し、開発の初期段階(Design Phase)からセキュリティを組み込む**「セキュリティ・バイ・デザイン」**のアプローチを採用します。教育とトレーニング: 開発者に対し、敵対的攻撃の原理や、セキュアなコーディング・データ管理のプラクティスについて定期的なトレーニングを実施します。
6. まとめ:AIセキュリティは「進化し続ける闘い」
AIセキュリティは、単なるバグ修正やファイアウォール導入といった静的な対策ではなく、AI技術の進化と、それを悪用しようとする攻撃者の革新が競い合う、動的な分野 です。
AIシステムの利便性が高まれば高まるほど、そのシステムへの依存度と、不正操作された場合の社会的インパクトは増大します。企業や組織は、AIを導入する際、その経済的利益だけでなく、**「データポイズニング」「敵対的摂動」「モデル盗難」**といったAI特有のリスクを正しく理解し、最優先で対処しなければなりません。
AIセキュリティを実現することは、単にシステムを守るだけでなく、AIの信頼性、公平性、そして持続可能性 を保証し、社会全体にAIの恩恵を安全に広げていくための、不可欠なステップとなります。
この進化し続ける脅威に対抗するためには、本ガイドで紹介したような、データ、モデル、運用の各レベルでの専門的な防御策を複合的に組み合わせた、徹底した「防御の多層化(Defense-in-Depth)」戦略 の確立が求められています。









































































 LINEで無料相談
LINEで無料相談 お問い合わせ
お問い合わせ